





From mathematics to Generative AI: A Fascinating Journey into Innovation

Ah, Artificial Intelligence! A term that makes us dream, fantasize, and sometimes frightens us a little. Long confined to science fiction films, AI is now everywhere, from our smartphones to scientific research. But if the recent surge of generative AI, with its models capable of creating text, images, or music, seems sudden to us, it is actually based on decades of research and solid theoretical foundations. Let’s explore together the roots of this fascinating discipline, understand its key concepts, and see how we arrived at this new era of AI that creates.
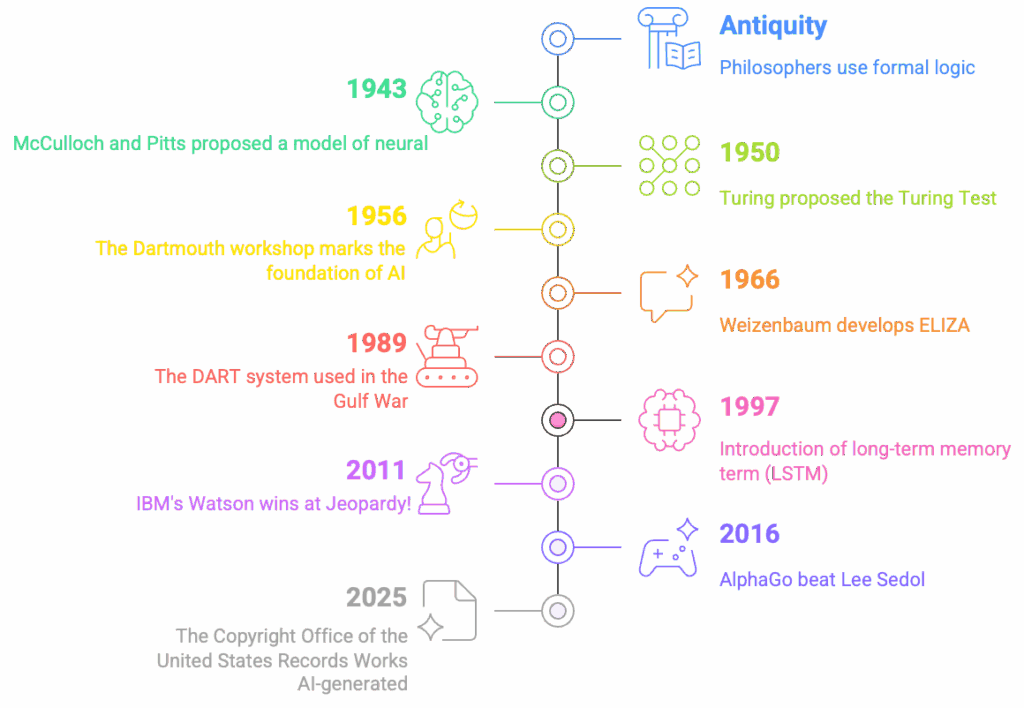
The Deep Roots of Artificial Intelligence
The idea of machines capable of “thinking” is not new. Some reflections can be traced back very far, notably to Aristotle’s work on logic. History is full of early examples of devices designed to imitate certain aspects of the mind or automate complex calculations. We think of mechanical calculators, automatons, or even the ideas of philosophers like Leibniz about a “universal calculator” to resolve disputes.
However, the field of artificial intelligence, as we know it, truly took off in the mid-20th century. A central figure of this period is Alan Turing, whose theoretical work as early as the 1940s laid the foundations for computability and machine thinking. He was reflecting on the intelligence of machines as early as 1941. His 1950 publication was followed by several radio broadcasts where he discussed the ability of digital computers to think.
The official birth act is often placed in 1956, during a conference at Dartmouth. It was during this event that John McCarthy proposed and used the term “Artificial Intelligence.” He chose this term to avoid associations with cybernetics and the influence of 0. This conference marked the beginning of a period of optimism, sometimes referred to as the era of “Look, Ma, no hands!” The first programs showed “amazing” capabilities when the computer did something “remotely intelligent.” Notable successes included the first programs capable of playing chess. The Perceptron, an early neural network architecture, also emerged.
Despite these promising beginnings, the path was fraught with obstacles. The field experienced periods of stagnation and budget cuts, known as “AI winters.” These setbacks were often due to the limitations of the systems of the time, especially when faced with more difficult tasks where they failed. Common sense knowledge problems and combinatorial explosion were major challenges. Early programs were limited by memory size and speed. Later, an “agent” view (an entity capable of acting in an environment) became widely accepted in the definition of AI.

Key Concepts of Machine Learning: The Heart of Modern AI
Over time, the dominant approach within AI has become machine learning. The idea is simple: instead of explicitly programming a machine for each task, it is given the ability to learn from data.
In this framework, models learn to identify patterns or make predictions. A common goal is to predict the value of a target variable for a new input without knowing the exact function that generates the data. For this, a training dataset is used. The model, which has a number of parameters (such as the coefficients of a fitting polynomial), adjusts these parameters to minimize an error function that measures the discrepancy between its predictions and the actual values in the training data.
The complexity of the model is an important issue. If a model is too simple, it will not be able to capture the structure of the data. If it is too complex, it risks adapting too specifically to the training data (this is called overfitting) and performing poorly on new data. To choose the right complexity, the available data can be partitioned into a training set and a validation set (or hold-out set). Techniques such as regularization are also used to help control the model’s complexity.
Working with high-dimensional data (i.e., data with many input variables) poses serious challenges and influences the design of learning techniques. Concepts from information theory, such as entropy or mutual information, are also relevant in this field.
Different learning approaches are distinguished. Supervised learning, for example, involves a human “teacher” who provides labels for the data. Unsupervised or semi-supervised learning allows the model to learn from large amounts of unlabeled data.

The Evolution Towards Generative AI and Large Language Models (LLMs)
The recent success of AI, particularly in content generation, is largely due to the advent of models of unprecedented size and new architectures. Large Language Models (LLMs) are a prime example. These are language models with a very large number of parameters, typically in the order of a billion or more.
These models are based on deep neural networks. For a long time, recurrent neural network (RNN) architectures were preferred for processing sequential data like text, but they had disadvantages for parallelizing computations. A major turning point occurred in 2017 with the suggestion of the Transformer architecture, which, based on an attention mechanism, proved to be very efficient for processing sequential data while being parallelizable during training. It was the advent of this architecture that allowed researchers to significantly increase the size of their models.
Most LLMs are trained through a generative pre-training process. This means that given a large set of textual data, the model learns to predict tokens (words, parts of words, or characters). There are two main styles: autoregressive (like the GPT style, predicting the next token in a sequence) and masked (like the BERT style, predicting missing tokens in a sequence). This pre-training is done on massive amounts of unlabeled text, from corpora such as Common Crawl, The Pile, Wikipedia, or GitHub. The training corpora have grown from a few billion words for early models like GPT-1 (985 million words) or BERT (3.3 billion words) to trillions of tokens today, as evidenced by Google’s latest engine, Gemini 2.5.
This large-scale pre-training is extremely computationally expensive. Once pre-trained, LLMs can be adapted to more specific tasks through fine-tuning, a form of transfer learning. Various methods exist, ranging from retraining all parameters to adding layers or adapters, or even adjusting the prompt (the natural language query) without modifying the model itself (prompt tuning). Instruction fine-tuning is particularly useful for making the model respond specifically, for example, as an assistant.
LLMs have fascinating properties. Their performance improves quite predictably with the size of the model, the size of the data, and the amount of computation used for training – empirically observed relationships called “scaling laws.” More surprisingly, these large-scale models can suddenly acquire substantial capabilities that were not present in smaller models, known as “emergent abilities.” These capabilities, such as arithmetic reasoning or understanding complex texts, often cannot be predicted by simple extrapolation.
However, it is crucial to note that these models are not without flaws. They can exhibit biases inherited from the training data, whether related to discriminatory stereotypes (sexist, racist, etc.), political biases, or linguistic biases that favor certain cultural perspectives. The prompt itself can also introduce biases. To mitigate these biases, it is necessary to diversify the AI community, the sources of training data, and give more weight to factual data, with regular human oversight.
LLMs are evaluated using various metrics, the most common being perplexity, which measures the model’s ability to predict a text corpus. Task-specific benchmarks, such as question-answering datasets (open or closed) or text completion tasks, as well as evaluations constructed in a contradictory manner to highlight weaknesses, are also used.
From ancient dreams of automatons to probabilistic models and neural networks, artificial intelligence has come a long way. The current phase, dominated by generative AI and LLMs, is not a revolution out of nowhere, but the culmination of decades of research, theoretical progress (such as the Transformer architecture), and access to massive amounts of data and computational power.
These models are capable of impressive tasks, but it is fundamental to understand their mechanisms (from pre-training to fine-tuning), their properties (scaling laws, emergent abilities), and their limitations (especially biases).
We are far from having explored everything. Research continues, seeking even more efficient architectures and better methods to align these models with our expectations and values. AI continues to evolve, and understanding its foundations is the first step to navigating (and perhaps even participating in) this remarkable technological transformation.

Sources:
A Brief History of Large Language Models, DATAVERSITY
Pattern Recognition and Machine Learning, edition 2006, by Bishop
AI Used: Google NotebookLM, Napkin, Mistral Le Chat, Adobe Firefly